Chinese Whispers Kümeleme Algoritması
Chinesne whispers (CW) kümeleme algoritması doğal dil işleme uygulamaları için C.Biemann tarafından 2006 yılında geliştirilmiştir. CW, denetimsiz bir öğrenme algoritmasıdır yani dil hakkında detaylı bilgiye ihtiyaç duymadan doğal dil işleme problemleri için kullanılabilmektedir. Language seperation, part of speech tagging, word sesse induction kullanım alanlarında bazılarıdır. İsminden de anlaşıldığı üzere, herkesin bildiği kulaktan kulağa çocuk oyunundan esinlenilerek oluşturulmuştur. Algoritmanın amacı birbirine aynı şeyleri söyleyen kişilerin kümelenmesinin simüle edilmesidir. CW bu amaçla, ağırlıklı ve yönsüz grafları kullanmaktadır.
Algoritmanın yapısı şu şekildedir:
Initialize:
forall vi in V: class (vi) = i;
while changes:
forall v in V, randomized order:
class (v) = highest ranked class in neighborhood of V;
Algoritma şu şekilde çalışmaktadır, ilk olarak kümelenecek tüm veriler farklı bir sınıfa atanır. Yani, başlangıçta veri sayısı küme sayısına eşit olmaktadır. Daha sonra her iterasyonda tüm veriler rastgele sıra ile tek tek seçilir ve kümesi, en kuvvetli sınıf ile aynı olarak ayarlanır. En kuvvetli sınıf, mevcut düğümün komşuları ile olan ağırlıklarının en büyük olduğu sınıftır. Eğer ağırlıklar eşit ise, en yüksek ağırlıklar arasından rastgele seçim yapılarak kümeler güncellenir. CW algoritmasının orijinalinde düğümler anlık olarak güncellenmektedir. Bunun anlamı aynı iterasyon devam ederken düğüm sınıfları güncellenmeye devam etmesidir.
Ağırlıklı graflara alternatif olarak ağırlıksız graflar ile de algoritmanın kullanılması mümkündür. Ağırlıksız graflar kullanıldığında, ağırlığı en yüksek olan yerine en fazla bağın kurulduğu sınıf, mevcut düğümün sınıfını belirlemektedir. Şekil 1.’de ağırlıksız ve yönsüz küçük bir grafın 2 iterasyonda kümelenmesi gösterilmiştir. Şekilde grinin farklı tonları farklı sınıfları temsil etmektedir.
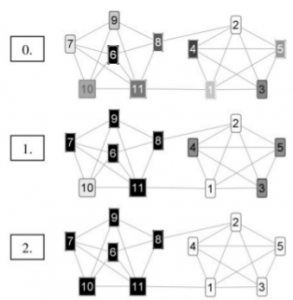
Şekil 1. 11 düğümlü bir grafın CW ile iki iterasyonda kümelenmesi
Doğal dil işleme uygulamalarında, kelimeler için co-occurence graflar kullanılmaktadır. Co-occurence grafları kelimelerin baz alınan dokümanlarda, beraber bulunmalarına dayalı olarak oluşturulan graflardır. İki kelime ne kadar fazla bir arada bulunmuşsa, iki kelime arasındaki co-occurence değerleri o kadar yüksek olmaktadır. CW’da graftaki düğümler kelimelerdir ve düğümleri bağlayan bağlantıların ağırlıkları kelimelerin birbirleri ile olan co-occurence ilişkileridir.
Ağırlıklı graflarda mevcut düğümün güncellenmesi Şekil 2.’de gösterilmiştir.
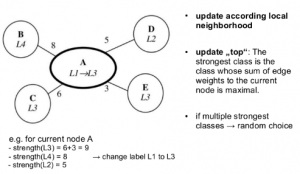
Şekil 2. Ağırlıklı grafta bir düğümün güncellenmesi
Şekilde L1 etiketine sahip A düğümü, kendisine bağlı olan düğümlerden ağırlığı en fazla olan etiket L3 etiketine sahip olmaktadır. Etiketlerin kuvvetleri sırasıyla, L2 = 5, L3 = 3+6 = 9 ve L4 = 8 dir. Buna göre, A düğümünün etiketi L3 olarak değiştirilmiştir.
CW algortiması, üzerinde çalışılan graf büyüdükçe daha iyi sonuç vermektedir. Algoritmanın çalışma zaman karmaşıklığı, graf köşe sayısına bağlı olarak lineerdir. Bu CW algoritmasının çok büyük grafları çok hızlı bir şekilde kümeleyebilmesi anlamına gelmektedir. Yayında yazarlar 1.5 milyon düğüme sahip bir grafın 20’den daha az iterasyon ile kümelenebileceğini belirtmiştir.
Avantajlarının yanında, algoritmanın analizinin zor olması, rastgeleliğe dayalı olduğundan non-deterministik olması ve düğüm durumu gibi durumlarda eğitimin tamamlanamaması gibi dezavantajlara sahiptir.
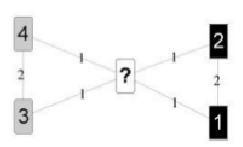
Şekil 3. Kümelemede düğüm durumu
Şekil 3’te soru işareti ile gösterilen düğüm sürekli farklı bir sınıfa ait olabilmektedir. Ancak bu durumun gerçek veriler üzerinde gerçekleşmesi nadirdir. Küçük graflardaki performansın geliştirilmesi için ilk iterasyonlarda kümelemeyi yavaşlatmak amacıyla algoritmanın ikinci bir versiyonu önerilmiştir. Buna göre algoritmanın yeni hali şu şekle dönüşmektedir:
Initialize:
forall vi in V: class (vi) = i;
for iteration i from 1 to total_iterations:
mutation_rate = 1/(i2);
forall v in V, randomized order:
class (v) = highest ranked class in neighborhood of V;
with probability mutation_rate:
class (v) = new unused class;
Eklenen mutasyon katsayısı sayesinde ilk iterasyonlarda düğümlere daha önce kullanılmayan bir sınıf atayacak ve daha yavaş bir şekilde kümeleme yapılacaktır.
CW Uygulamaları
CW Bi-partite clique yapılarını kümelemek amacıyla kullanılmıştır. Bi-partite clique yapıları birbiri ile daha fazla ilgisi olan elemenların daha fazla bağ kurduğu ve kendisi gibi guruplarla daha az bağlantısı olan graflara denir. CW bu problemin çözümünde kullanılmıştır. Sonuçlar, algortimanın düğüm sayısı arttıkça daha başarılı bir performans ortaya koyduğunu göstermektedir.
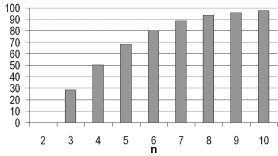
Şekil 4. n düğümlü kümelerin CW ile kümelenmesinde başarrı oranları
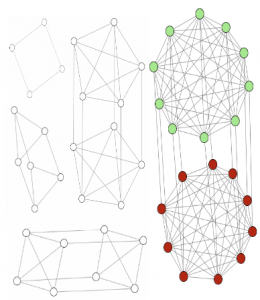
Şekil 5. Farklı n sayılarına sahip graflar
CW, dillerin ayrımında da kullanılmıştır. Kelimelerin co-occurence grafları elde edildikten sonra algoritma çalıştırılmıştır. Elde edilen sonuçlar mükemmele yakın başarım sağlandığını göstermiştir. İki dilde ortak bulunan kelimeler için soft-partitioning yöntemi kullanılabileceği belirtilmiştir. Yani, düğümlerin iki sınıfa da farklı oranlarda ait olabileceği bir yöntem önerilmiştir. Ancak, bu kelimelerin sadece bir sınıfa atanması performansı düşürmediği saptanmıştır.
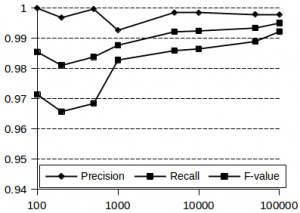
Şekil 6. 7 dilin ayrımı için elde edilen sonuçlar
Ayrıca, CW zarf, fiil, isim gibi kelime tiplerinin kümelenmesinde de kullanılmıştır. Bu uygulama için co-occurence grafı yerine farklı bir graf kullanılmıştır. Kelimelerin, birbirinin sağında ve solunda birlikte kullanılmasına göre farklı bir co-occurence grafı oluşturulmuştur. Daha sonra bu graftan yararlanılarak, ikinci dereceden komşuluk grafı oluşturulmuş ve bu grafa göre kümeleme işlemi gerçekleştirilmiştir.
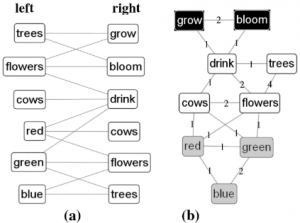
Şekil 7. Kelimelerin birbiri ardına gelmesi ile oluşturulan graf (a) ve ikinci dereceden co-occurence grafı (b)
Şekil 7. (a)’da “grow” kelimesi ve “bloom” kelimesi ortak olarak “trees” ve “flowers” kelimeleri ile bağlantılıdır. Bu yüzden (b)’de bu iki kelimenin arasındaki ağırlık 2 olmuştur. Oluşan (b) grafı kullanılarak kelimeler kümelenmiştir. Yayında İngiliz Ulusal Sözlüğü kullanılarak kümeleme işlemi gerçekleştirilmiştir. Sonuç olarak algoritma 26 tanesi 100 kelimeyi geçen 282 adet küme üretmiştir. Kümelerin saflığı %88.8 olarak elde edilmiştir.
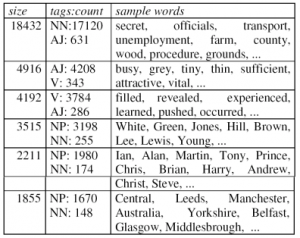
Şekil 8. Kümeleme sonucu üretilen bazı kelime grupları
Sonuç olarak CW algoritması, çok basit olmasına rağmen çok etkili bir yöntemdir. Çok büyük miktarda veriyi hızlı bir şekilde kümeleyebilmektedir. Bunların yanında ağırlıklı ve ağırlıksız graflarla kullanılabilmesi, hard-partitioning ve soft-partitioning yöntemlerinin kullanılabilmesi gibi esneklikler tanıyabilmektedir. Doğal dil işleme uygulamalarının yanında resim sınıflandırma gibi farklı alanlarda da kullanılması mümkündür.
Bu yazıda C. Biemann tarafından yapılan çalışmadan yararlanılmıştır[1].
[1] Biemann, C. (2006, June). Chinese whispers: an efficient graph clustering algorithm and its application to natural language processing problems. In Proceedings of the first workshop on graph based methods for natural language processing (pp. 73-80). Association for Computational Linguistics.