Makine öğrenmesi ve derin öğrenme konularına çalışmaya yeni başlayanlar ilk aşamalarda gelenekselleşmiş bazı problemlerin çözümleri üzerinden konuları öğrenir. Örneğin el yazısıyla yazılmış rakam görüntülerinden oluşan MNIST veri seti kullanılarak el yazısı görüntüsünden rakam tespitinin yapılması ya da Reuters haberlerinin otomatik olarak sınıflandırılması gibi.
Yöntemlerin öğretilmesi, karşılaştırılması gibi senaryolar için bazı veri setleri o kadar sık kullanılmaktadır ki bu veri setleri Keras, TensorfFlow, Caffe gibi frameworklarda birkaç satır içerisinde eğitim, test veri setleri olarak hazır bir şekilde kullanıma sunulmaktadır. Örneğin Keras’ın veri seti kütüphanesinde aşağıdaki veri setleri * import edilebilir şekilde bulunmaktadır. Bu verilerin indirilmesi, eğitim seti ve test seti olarak parçalara ayrılması işlemleri için alt yordamlar hazır olarak tanımlıdır.
Örneğin:
from keras.datasets import boston_housing (x_train, y_train), (x_test, y_test) = boston_housing.load_data()
Keras tarafından sunulan bazı hazır veri setleri şunlardır:
- CIFAR10 small image classification
- CIFAR100 small image classification
- IMDB Movie reviews sentiment classification
- Reuters newswire topics classification
- MNIST database of handwritten digits
- Fashion-MNIST database of fashion articles
- Boston housing price regression dataset
Veri seti hazırlanması ve kullanıma sunulması zahmetli bir iştir. Bu kolay kullanımlar sayesinde belki de birçok kişinin daha en baştan konuyla ilgili hevesini kaybetme riski azalmaktadır.
Akademik bir çalışma ya da çözmemiz gereken bir problem için veri hazırlama süreci tamamen manuel olarak yapıldığında çok zahmetli olabilir. Örneğin elimizde binlerce metin verisi varsa bunların bir dosyada açılıp teker teker karşısına ilgili etiket (ekonomi, spor, sanat, vb. ) yazılması yerine bunu bir test çözer gibi hızlıca uygun etiketi tıklayarak bu işi çok daha kısa sürede tamamlayabiliriz. Ayrıca bu veri setinin etiketlenmesi işi bir ekip tarafından yapılacaksa verilerin web tabanlı bir ortamda otomatik olarak dağıtılması dosyaların manuel olarak bölünüp daha sonra bir araya getirilmesinden çok daha hızlı olacaktır. Bazı durumlarda etiketleme için birden fazla uzman görüşü gerekebilir, bunun için aynı veri elementinin birden fazla kişiye sorulması sağlanabilir.
Böyle bir sistemi kendi ihtiyacımıza göre tasarlayabiliriz. Ya da var olan seçeneklerden birini kullanabiliriz. Bu yazının amacı sizlere bazı veri etiketleme araçlarını tanıtmaktır.
1 – LabelMe
LabelMe, Görüntülerin etiketlenmesi ve onlara açıklayıcı bilgilerin eklenmesini sağlayan Web tabanlı bir görüntü etiketleme aracıdır. Görüntü veri tabanları oluşturulmasını ve paylaşılmasını kolaylaştırmaktadır. MIT, Computer Science and Artificial Intelligence Lab. tarafından geliştirilmiştir.

2- DataTurks
DataTurks görüntü ve metin verilerinin etiketlenmesi için farklı seçenekler sunmaktadır.
Örnek kullanım:
Twitter’dan topladığımız verileri konuya göre etiketlemeye sunmak için her satırda 1 adet Tweet olacak şekilde toplanan veriler bir dosyaya kaydedilir ve sisteme yüklenir.
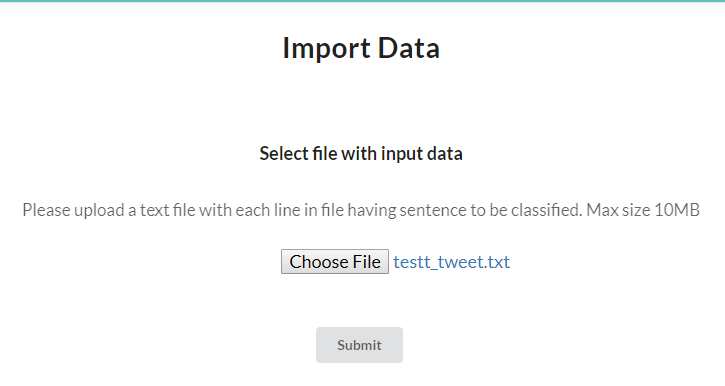
Daha sonra arayüzden bir proje oluşturulur. Bu projeye önceden tanımlı sınıfların isimleri aralarında virgül olacak şekilde ilgili yere yazılır.
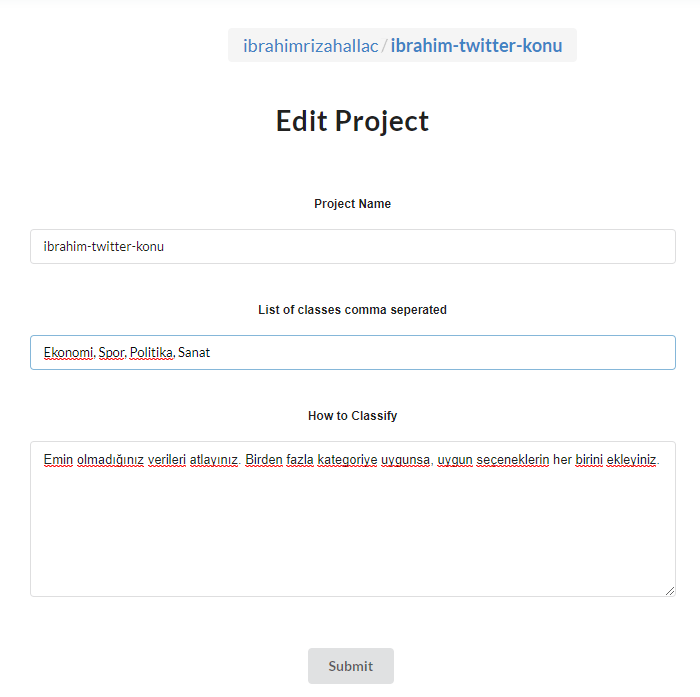
Proje kaydedilir ve veriler sırayla etiketlenmek üzere kullanıcıya sunulur
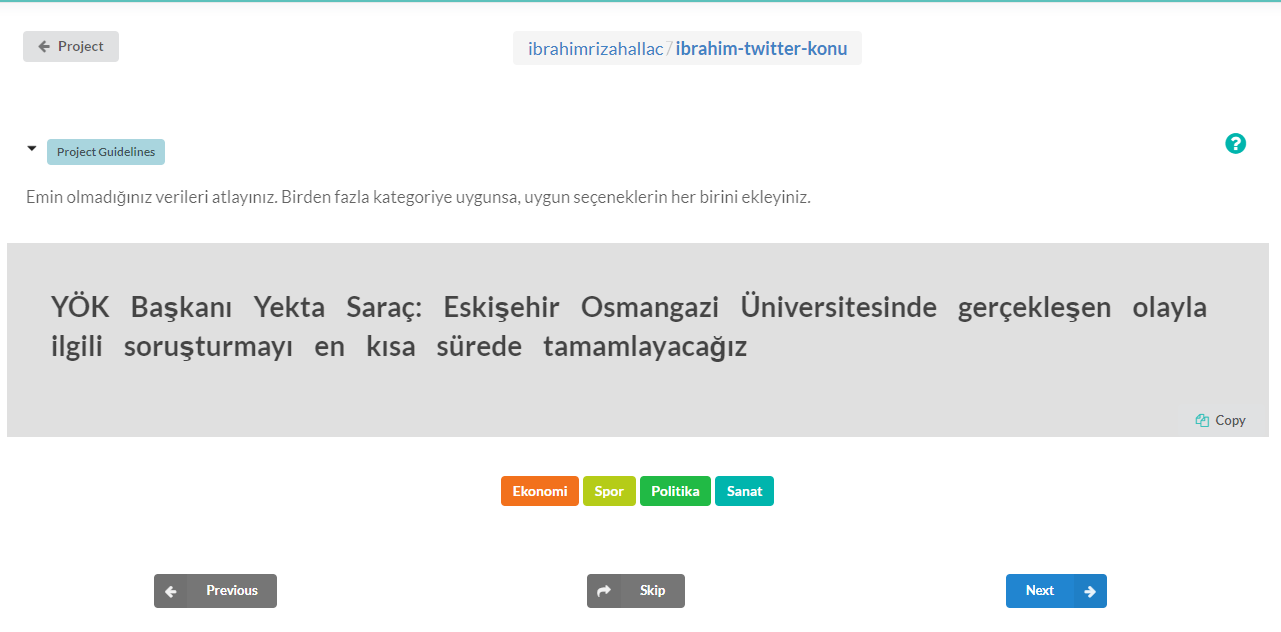
İnceleyebileceğiniz diğer araçlar:
- Corpus Tool http://corpustool.com/
- LabelBox https://www.labelbox.io/
- Gate https://gate.ac.uk/teamware/
- ART project aber.ac.uk/en/cs/research/cb/projects/art/software/
- RectLabel https://rectlabel.com
- VoTT: Visual Object Tagging Tool https://github.com/Microsoft/VoTT/
İhtiyaçlarınıza uygun bir veri seti daha önce yukardaki araçlardan birisiyle hazırlanmış ve ücretsiz olarak sunuluyor olabilir. Linklerdeki geçmiş dataset’ler bölümlerinin ziyaret edilmesinde fayda var.
Not: Dataturks’ten Mohan Gupta’ya platformu kolayca keşfetmeme yardımcı olduğu için teşekkürlerimi sunuyorum.
I would like to thank Mr. Mohan Gupta for his kind help in making dataturks platform very easy to discover for me.
İbrahim R. HALLAÇ